DNA Sequence Analyzer for quick sequence checks
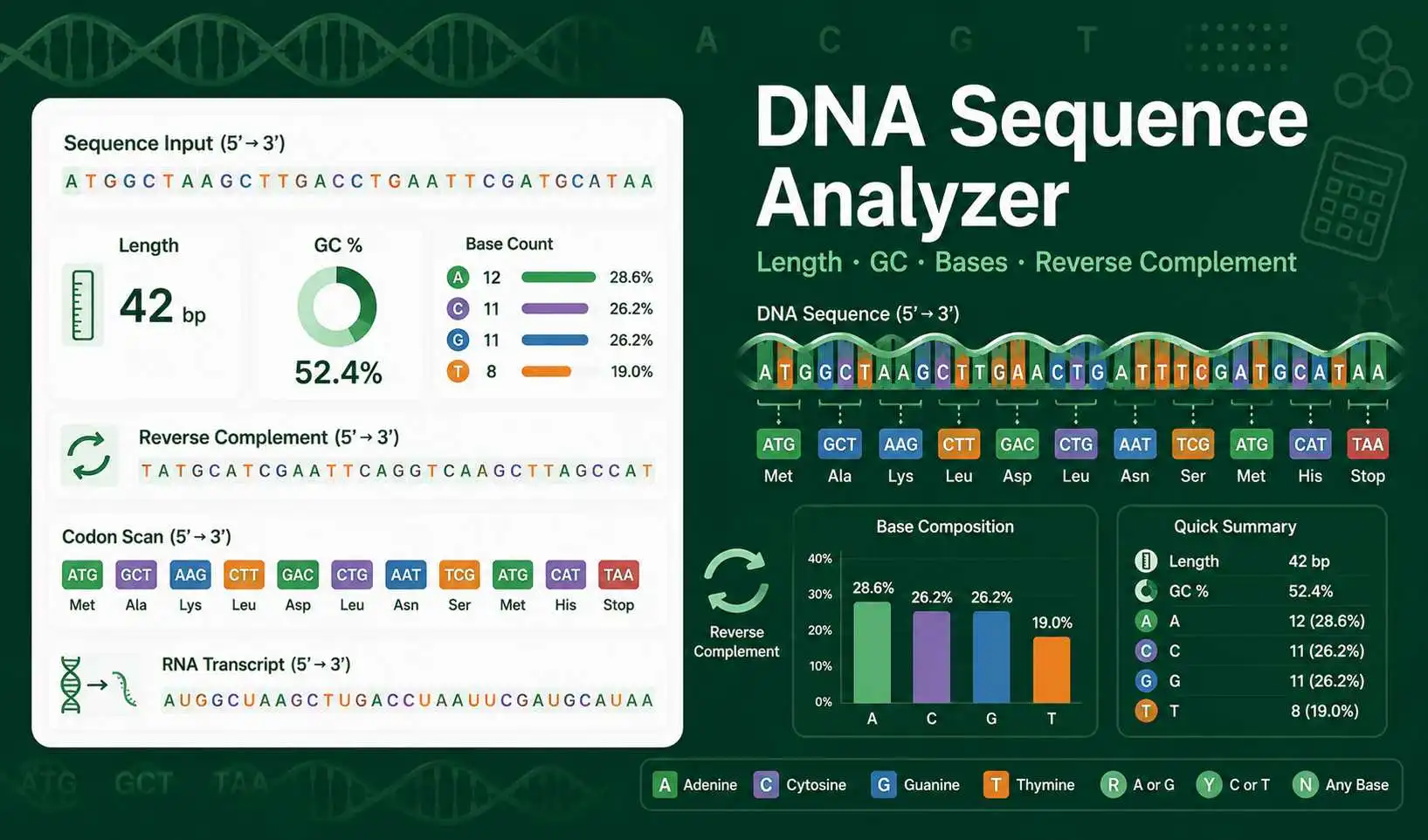
A DNA Sequence Analyzer reads a nucleotide sequence and reports its most useful properties. It gives direct answers for sequence length, base composition, GC content, AT content, reverse complement, RNA transcript, codon count, and simple quality warnings.
Students can use it to understand DNA sequence structure. Lab workers can use it for quick checks before PCR, cloning, sequencing, and primer review. Teachers can use it to create practical examples for genetics, molecular biology, and biotechnology lessons.
How to use the DNA Sequence Analyzer
Paste a DNA sequence into the input box. You can paste a plain sequence or a FASTA-style entry. The tool ignores FASTA headers, spaces, numbers, and line breaks. It accepts A, C, G, T, and standard IUPAC DNA ambiguity codes such as N, R, Y, S, W, K, M, B, D, H, and V.
Use the result cards to read the main values first. Length shows the total accepted DNA bases. Exact bases count only A, C, G, and T. Ambiguous bases show symbols that represent more than one possible nucleotide. The copy button helps you move the results into a lab notebook, worksheet, or report draft.
DNA sequence length, GC content, and base composition
GC content is the percentage of guanine and cytosine bases in the exact part of the sequence. The formula is G plus C divided by A plus C plus G plus T, multiplied by 100. AT content uses the same denominator and reports adenine plus thymine percentage.
GC content affects melting behavior, primer design, PCR conditions, and sequence stability. A very low GC sequence can bind weakly. A very high GC sequence can form strong secondary structures or require adjusted amplification conditions. For a focused percentage check, use the GC Content Calculator.
Reverse complement and RNA transcript output
The reverse complement helps you read the opposite DNA strand in the 5′ to 3′ direction. The analyzer pairs A with T and C with G. It also supports IUPAC ambiguity complements, so R becomes Y, K becomes M, and N remains N.
The RNA transcript output replaces thymine with uracil. This is useful when you want a simple transcription-style conversion from a coding DNA sequence to an RNA sequence. For a dedicated strand tool, use theReverse Complement Generator.
Codon scan and coding sequence review
The codon scan groups the sequence into triplets from the first base. It reports the number of complete codons, ATG start codons, and stop codons in frame 1. This helps you notice whether a sequence may contain a coding region or whether the pasted sequence has a frame problem.
A coding sequence usually works in groups of three bases. If the length is not divisible by 3, the final bases do not form a full codon in the selected frame. This tool does not replace a full ORF search across all six reading frames, but it gives a fast first-pass scan.
When to use this DNA Sequence Analyzer
Use this tool before writing a lab report, checking a primer region, reviewing a cloning insert, preparing a sequencing explanation, or teaching nucleotide composition. It also helps when you need to clean a pasted FASTA sequence and quickly see whether unsupported characters are present.
Before real lab work, verify the strand direction, exact sequence, target specificity, expected amplicon size, restriction sites, primer pair behavior, and supplier requirements. Educational analysis gives a useful starting point, but critical PCR, cloning, and sequencing decisions need independent confirmation.
For background on FASTA sequence records and biological sequence formatting, see the NCBI information about FASTA sequence format.NCBI FASTA format