DNA to Protein Translator for codon reading
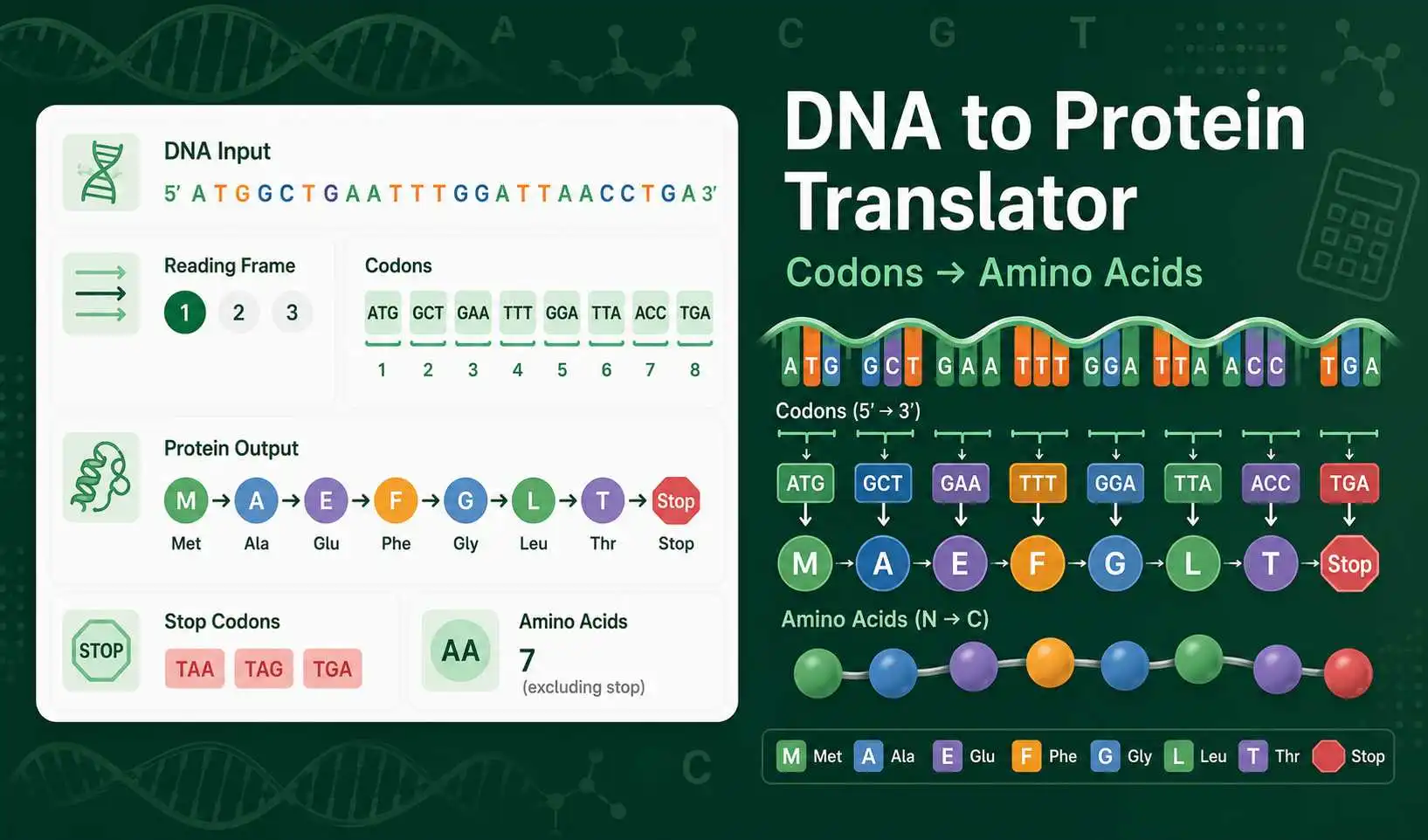
A DNA to Protein Translator converts a nucleotide sequence into an amino acid sequence. It reads DNA bases in groups of three called codons. Each codon represents one amino acid or a stop signal. This makes the tool useful for genetics homework, molecular biology classes, cloning checks, sequencing review, and protein expression planning.
The calculator accepts DNA letters A, C, G, and T. It removes FASTA headers, spaces, line breaks, and numbers. It then translates the selected reading frame using the standard genetic code.
How DNA translation works in this tool
Choose the forward strand if your sequence is already the coding strand. Choose reverse complement if your pasted sequence is the opposite strand. Then select frame 1, frame 2, or frame 3. The frame decides where the first codon starts.
The tool groups the selected sequence into codons such as ATG, GCT, or TAA. ATG is commonly used as a start codon. TAA, TAG, and TGA are stop codons in the standard code. You can compare frame results with the ORF Finder when you need to locate longer open reading frames.
DNA to Protein results explained
The protein sequence appears in one-letter amino acid format. For example, M means methionine, A means alanine, and G means glycine. The asterisk symbol means stop codon. The tool also reports DNA length, codons translated, stop codon count, GC content, estimated protein mass, and the longest simple ATG-to-stop region in the selected frame.
If one or two bases remain at the end, the tool ignores them because they do not form a complete codon. This is normal when a sequence length is not divisible by three. It may also show that the wrong frame was selected or that the sequence is partial.
Standard genetic code assumption
This translator uses the standard nuclear genetic code. That is the common educational code used for many textbook DNA translation examples. Some organisms, mitochondria, and special biological systems use alternative codon tables, so you should verify the code when working with non-standard genomes.
For a reference list of genetic codes and codon table variants, see the NCBI genetic code resource.NCBI genetic codes
Common mistakes in DNA to protein translation
The most common mistake is translating the wrong strand. A second common mistake is choosing the wrong reading frame. A third mistake is treating every ATG as the true biological start codon without checking the gene annotation, transcript model, or experimental design.
Internal stop codons may suggest a wrong frame, sequencing error, pseudogene, intron-containing genomic sequence, or partial fragment. If your goal is expression cloning, check the complete coding sequence, start codon, terminal stop codon, and vector reading frame carefully.
When to use a DNA to Protein Translator
Students can use it to learn codons, amino acids, reading frames, and stop codons. Teachers can use it to build translation examples for genetics lessons. Lab workers can use it for quick sequence checks before cloning, ordering primers, or reviewing a sequencing result.
For codon-level patterns after translation, use the Codon Usage Calculator. It helps you inspect how often each codon appears in a coding sequence.